教你破解cloudflare金盾5秒顺利爬取网站内容的方法

教你破解cloudflare金盾5秒顺利爬取网站内容的方法
home again现在网站多多少少都有ddos防护上cdn,不然裸着谁敢开网站啊。cloudflare作为cdn届的大佬,我们国内能和他相提并论的也只有百度云加速这一家了,但是百度云加速(su.baidu.com)有明显的劣势:需要备案;免费版不支持https。所以导致大批用户转投cloudflare(简称CF,下同)的怀抱。CF有一个非常有名的金盾5秒,随着攻击普遍增加(现在发起cc攻击成本越来越低),金盾5秒也越来越频繁的出现在我们眼前。魔高一尺,道高一丈,防御升级的同时,总有撕开防御口子的方法,这就是一场永无止尽的攻防战。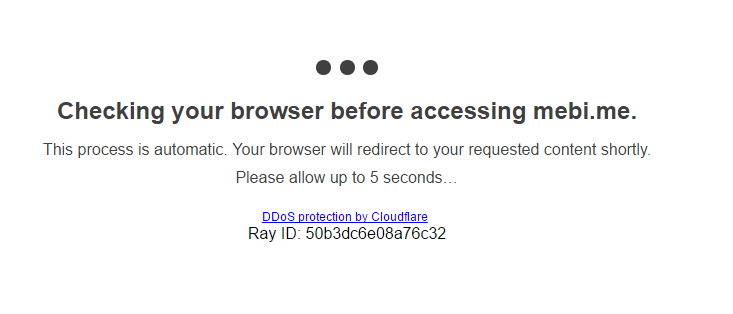
cloudflare-scrape介绍
cloudflare-scrape是一个简单的Python模块,用于绕过Cloudflare的反机器人页面(国内称作金盾5秒),以顺利抓取Cloudflare保护的网站内容。 Cloudflare会定期更改其技术,cloudflare-scrape也会相应升级程序。
安装
安装cloudflare-scrape非常简单,只需要安装python的cfscrape模块和node.js程序。
安装cfscrape模块
pip install cfscrape |
如果报错:AttributeError: ‘module’ object has no attribute ‘X509_up_ref’,请先执行如下命令,然后再执行上述命令
pip uninstall pyOpenSSL |
安装node.js
确保nodejs的版本在4.5或以上,不然会报错。查看nodejs版本方法为:node -v
Ubuntu / Debian |
使用
新建一个test.py文件,请熟悉vim编辑器的命令:i为编辑,Ese为进入命令模式,:wq为保存并退出
cd ~ |
在文件test.py里写入下面内容,将第四行中的http://somesite.com改为你的目标地址。
import cfscrape |
下面开始执行,就能看到网站内容在屏幕上滚动出来了。
python test.py |
如果需要将抓取的内容保存到本地,修改一下上述代码即可
import cfscrape |
再次运行python test.py后,就能在/root目录下看到名为test.html的文件,里面保存的就是公益站的源码了。博主是因为要爬取ssr账号,无奈对方网站开了CF金盾,就这能用这个方法了。
升级
因为CF的金盾在不断升级,cloudflare-scrape也要做相应的调整升级保证程序可用性。cf-scrape升级方法很简单
pip install -U cfscrape |
其他
- CF金盾会检测客户端是否支持JavaScript,安装nodejs的目的就在此。
- CF金盾常规方法是使用JavaScript检测页面,这个使用cfscrape就能解决。CF金盾偶尔也会使用reCAPTCHA(谷歌验证码)来进行检测,那就算你倒霉。